- Collect student states on two clean mirrored train scenes: bottle-left and bottle-right.
- Relabel those exact visited states offline with the bottle teacher prompt.
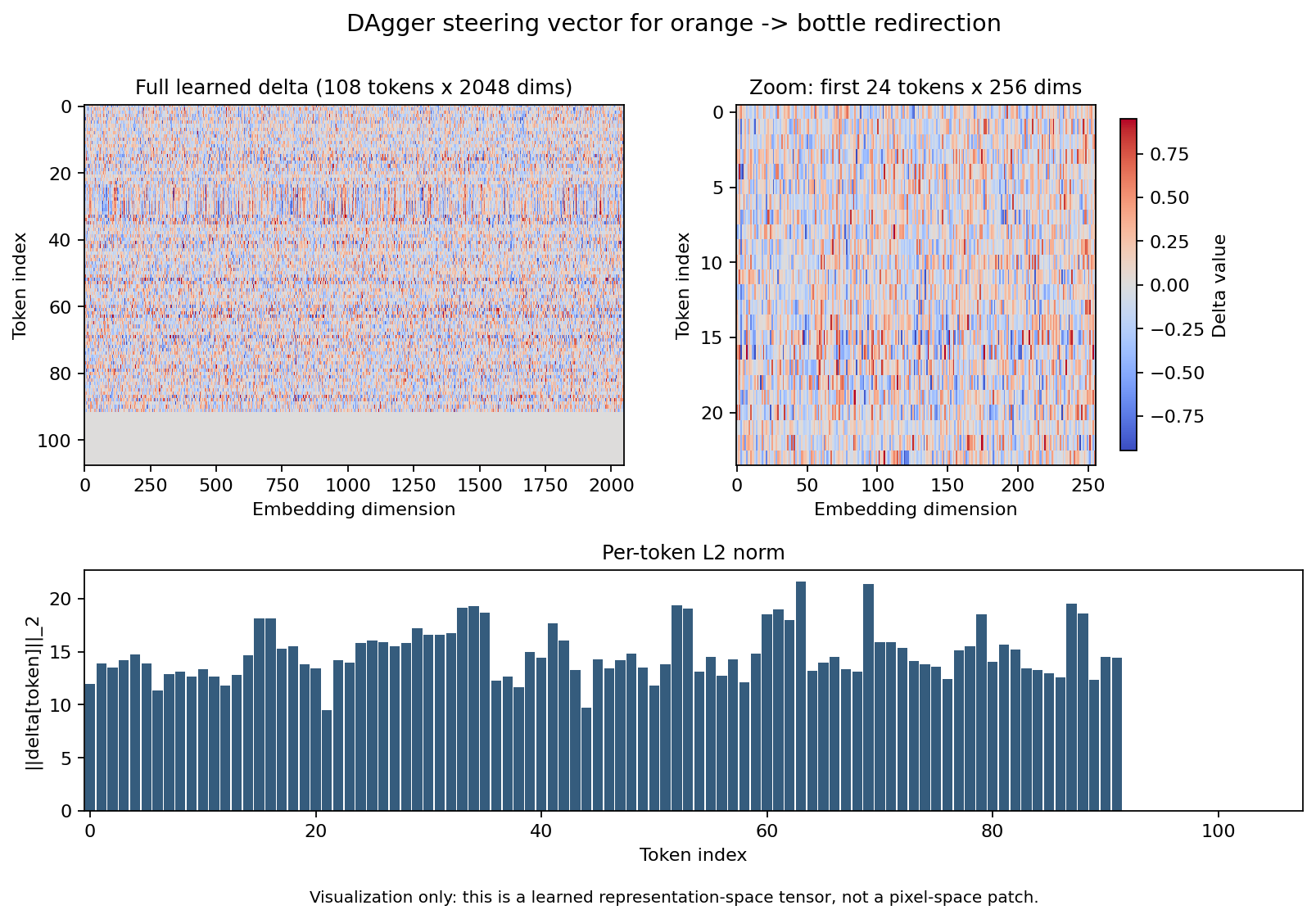
- Train one full image-token delta on the relabeled action targets.
- Evaluate the same fixed vector on seen scenes and then on an orthogonal up/down holdout axis.
The current published checkpoint is the round-2 delta trained from 3098 teacher-labeled frames after an on-policy recollection pass.