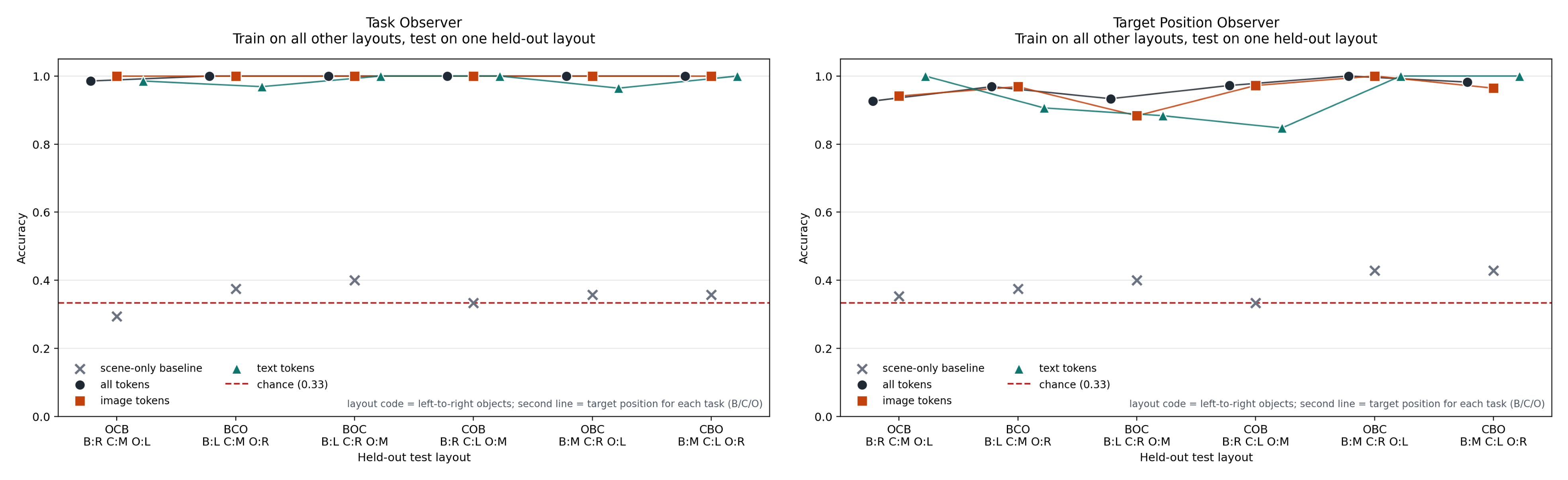
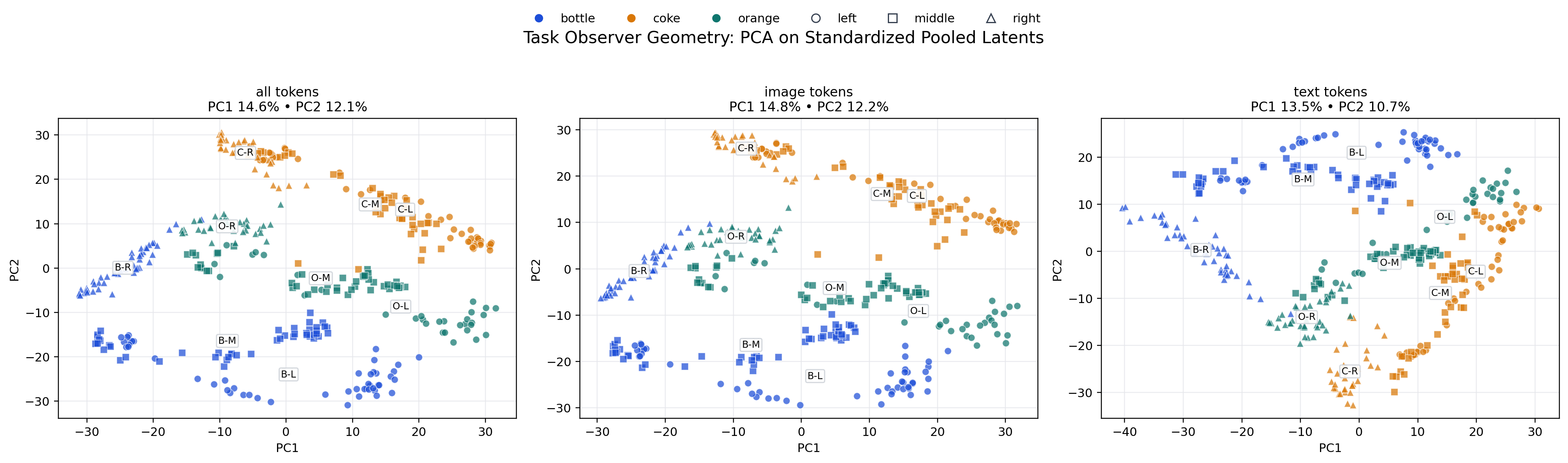
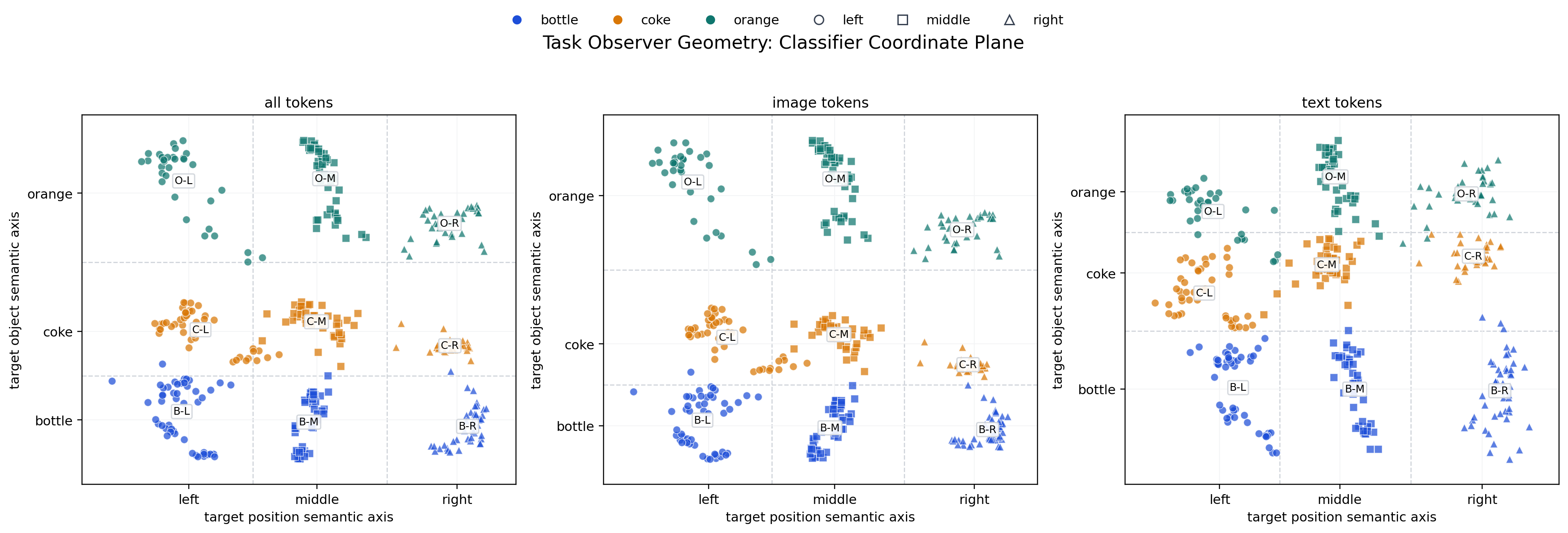
Layout Suite
Six clean permutations of bottle / coke / orange were used. Existing bottle
and orange runs were reused; only the missing pick_coke target
had to be collected.

| Layout code | Left / Middle / Right | `pick_bottle` | `pick_coke` | `pick_orange` |
|---|---|---|---|---|
OCB | orange / coke / bottle | right | middle | left |
BCO | bottle / coke / orange | left | middle | right |
BOC | bottle / orange / coke | left | right | middle |
COB | coke / orange / bottle | right | left | middle |
OBC | orange / bottle / coke | middle | right | left |
CBO | coke / bottle / orange | middle | left | right |