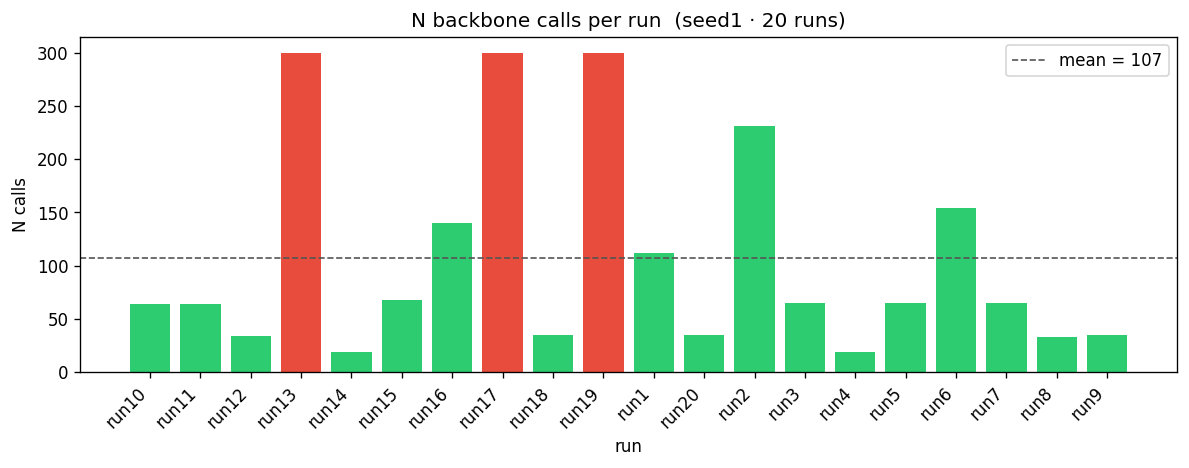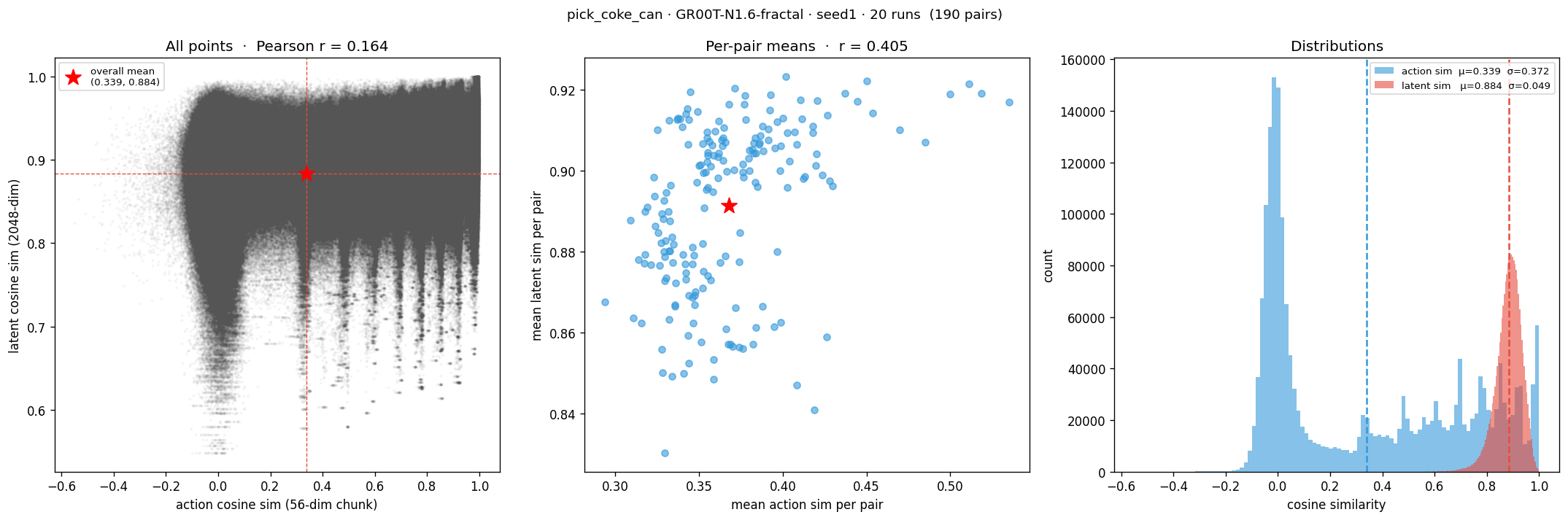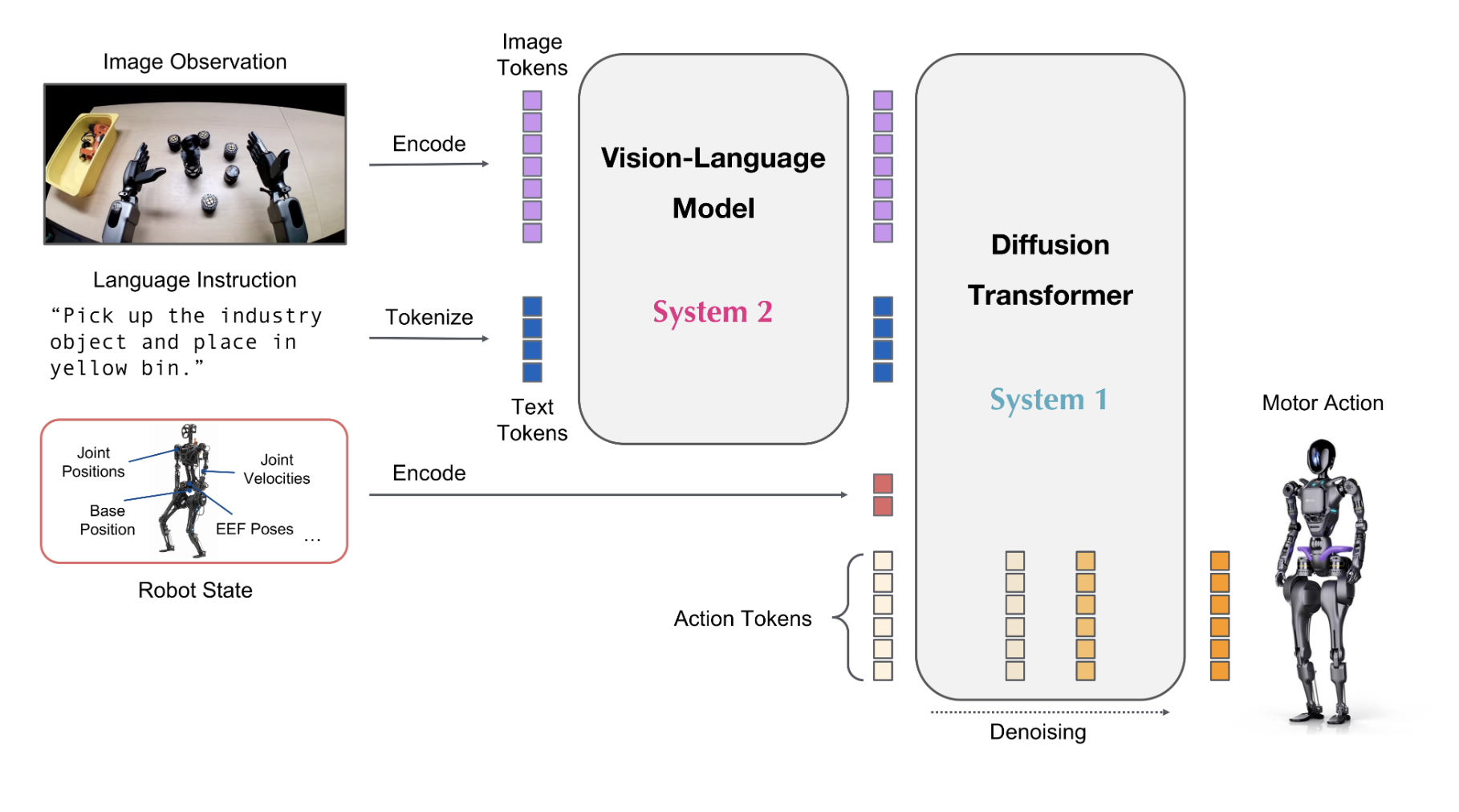
The conditioning tokens are extracted using a
register_forward_hook on the final layer of the System 2
transformer before its output is consumed by System 1’s cross-attention.
Each rollout step produces one embedding vector.
We collect embeddings across:
- 4 tasks — Pick Coke Can, Close Drawer, Open Drawer, Move Near
- Scene variants — SimplerEnv provides per-task visual variants (object placement, background, lighting)
- N steps per episode — sampled uniformly per rollout
Each embedding is labeled with its task and scene variant. Analysis then asks: which label dominates the latent geometry?